OCRとは
OCR(Optical Character Recognition/Reader、オーシーアール、光学的文字認識)とは、手書き文字や印刷された文字を含む紙書類を、イメージスキャナやデジタルカメラによって読みとり、コンピュータが利用できるデジタルの文字コードに変換する技術です。
OCRは、紙メディアとして保存されている情報を効率よくデジタル化することが可能です。デジタル化された情報は、プラットフォームを問わずあらゆる方面で活用することができます。

OCR(Optical Character Recognition/Reader、オーシーアール、光学的文字認識)とは、手書き文字や印刷された文字を含む紙書類を、イメージスキャナやデジタルカメラによって読みとり、コンピュータが利用できるデジタルの文字コードに変換する技術です。
OCRは、紙メディアとして保存されている情報を効率よくデジタル化することが可能です。デジタル化された情報は、プラットフォームを問わずあらゆる方面で活用することができます。
OCRは、「伝票(帳票)処理用OCR」と「文書(活字文書)OCR」の大きく2つに分類され、それぞれ「データ入力」や「文書管理」の用途で活用されています。
データ入力で用いられる原稿は、主に「伝票」や「帳票」と呼ばれ、定形および準定型文書となります。OCRの利用面から「伝票(帳票)処理用OCR」と分類されます。特長は、読み取ったデータを業務ソフトウェアと連携して、データ処理することが目的となります。最近では、免許証・保険証・マイナンバーカード・パスポートなどの本人確認にOCRを利用するケースも増加しています。(これら免許証などは活字文書として、文書OCRに区分するケースもあります。)
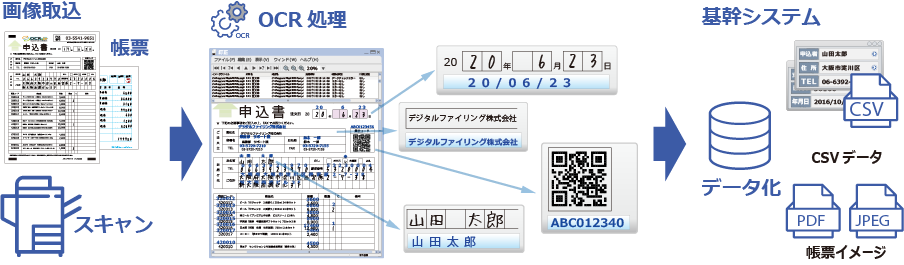
文書管理に用いられる原稿は、書籍、論文、契約書、新聞などあらかじめ形式の決まっていない文書(非定型文書)が対象となり、OCRの利用面から「文書OCR」と分類されます。特長は、キーワードで検索できるように全文のテキスト化を行ったり、読み取り結果を市販ソフトウェア(WordやExcel等)にて、再編集することに用いられます。また、名刺をOCRし、デジタル化した名刺情報を管理する「名刺管理」で利用するケースも多くあります。さらに、「名刺管理」は、CRM(顧客管理)・SFA(営業支援)などにシステム拡張され利用されています。
文書管理

名刺管理







OCRは、従来、人に変わって文字を読み取る効率的手段として使用され、紙文書をデジタルデータ化(テキスト化)することによって、様々な情報端末での利用が容易となりました。特に紙文書の多い業務では、人による入力作業を必要とせず自動でデジタルデータ化(テキスト化)できるOCRは有効です。また、「電子帳簿保存法」や「e-文書法」等の制定により、文書、伝票、会計帳簿、領収書等の電子化(ファイリング)が不可欠となっており、さらに、「働き方改革」に伴うRPAの普及により、紙文書のデジタル化がより一層求められることとなり、OCRの導入が加速しています。
・紙文書をデジタル化することにより、物理的な保管スペースを劇的に小さくすることができます。段ボール箱いっぱいの紙文書もタブレット内に収まります。

・画像情報をテキストデータ化することにより、メモリ容量を約700分の1にすることができます。
A4(モノクロ・400dpi)の画像データが1枚あたり約2MB として、A4一枚あたりに記載された文字が、日本語1000字程度であった場合に、テキストデータ約0.003MBになります。

・情報検索が素早く簡単にできます。
情報をテキスト化することによって、文書をイメージで保管する場合に検索機能を使って、欲しい情報を素早く検索できます。

・データの再利用が簡単にできます。
紙文書をテキスト化することにより、テキストエディターで、編集が可能となります。また、紙面上で表組になっているものをOCRで読み取り、タブ区切りで出力すれば、表計算ソフトのグラフ化機能を使って瞬時にグラフ化することもできます。

・RPAなどとの連携で、データ入力などの定型業務を効率化することにより、よりクリエイティブな作業に時間を使えます。

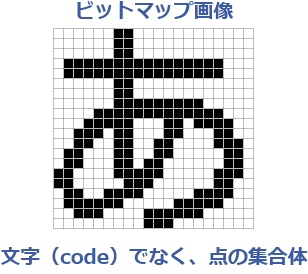
人は、新聞や雑誌などに印刷されている文字や街中の看板に書かれている文字などを特別に意識することなく【文字】として読むことができます。しかし、PC端末上はスキャナで取り込んだデータは、画像ファイル(ビットマップ画像)として捉えられ、文字ではなく、四角形の画素(ピクセル)の集合体として捉えられています。
新聞をスキャンした画像

例えば、新聞や雑誌などの紙面の内容は、表題と図と文章などで構成されています。また、文章については、いくつかの段組みから構成されています。このような紙面のOCR(文字認識)を行うためには、画像の中から文字の部分を見つけて、読む順序を決めてやる必要があり、この処理をレイアウト解析と言います。OCR処理を実施する前に、文字領域、図領域、罫線領域など領域設定を実施した一例として、新聞画像のレイアウト解析した画像が次の画像となります。
最近では、文書レイアウトの、テキスト、図、表、などの領域をページ単位で解析し領域識別するだけでなく、文書レイアウトの論理構造(タイトル(章、節、など)、著者名、本文、ページ番号、柱、など)を抽出する書籍単位の処理を行う論理構造解析まで実施できるように進化しています。

新聞のレイアウト解析を行った一例

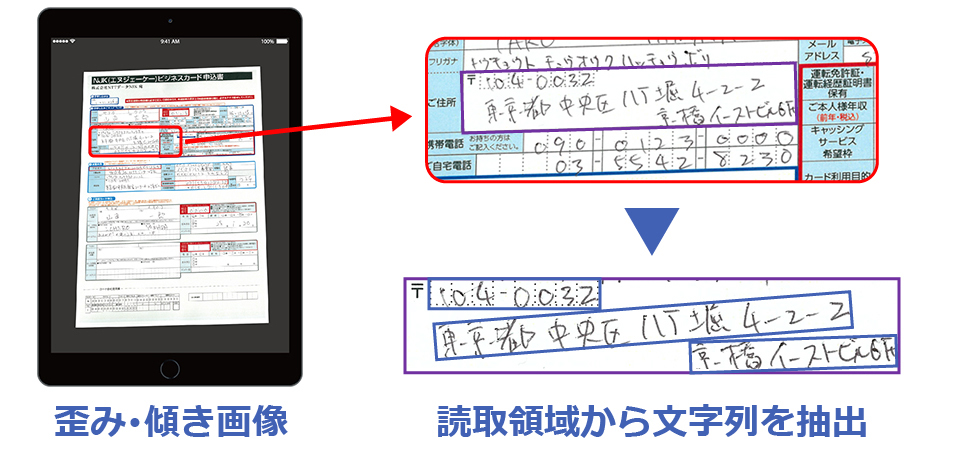
レイアウト解析で文字領域として抽出された画像から、文字列を抽出します。図のように1行ごとに分解し、この処理を行の切り出しと呼んでいます。
最近では、AI(深層学習)のCNN(Convolutional Neural Network)やRNN(Recurrent Neural Network)の手法と従来OCR技術を応用し、タブレットやスマホで撮影した画像に見られる歪み・傾き画像からも文字列の抽出を可能にしてします。
文字領域で「行」の切り出しを行った例

AI(深層学習)を応用した例
行の切り出しされた画像1行を1文字ごとに分解します。この処理を文字の切り出しと呼んでいます。この処理は、一定のエリアを上から下に移動しながら、文字と交差する数をカウントして、この値が「0」(白のすき間)のところを文字と文字の区切りとして判断する方法などがあります。
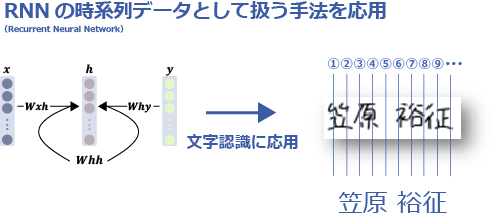
最近では、AI(深層学習)のRNN(Recurrent Neural Network)の手法を利用し、文字列画像を時系列データとして扱うことで、手書き単語認識(知識処理)に応用しています。文字列単位で学習により、文字単位での分割が困難な接触文字や活字と手書き文字が混在した文書などの認識精度を向上させることが可能となります。
1行から「文字」の切り出しを行う方法

AI(深層学習)を応用した例
次に、1文字単位で切り出された文字を認識処理することになります。
文書内にある個々の文字は、「文字の大きさ(文字サイズ)」や「字体(フォント)」が異なり、紙面や印刷の状態によっては、「つぶれ」や「かすれ」などがあります。
これらの異なった条件に対して、正確にOCR(文字認識)を行うためには【1.正規化】【2.特徴抽出】【3.マッチング】【4.知識処理】といった工程で処理を実施します。
一般的な文字認識処理手順
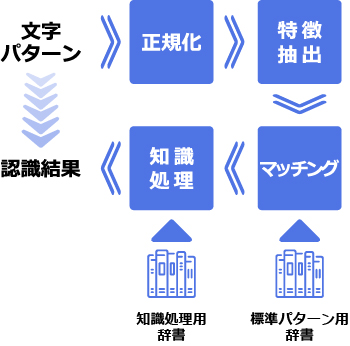
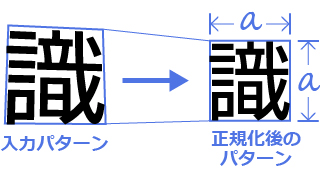
OCR(文字認識)処理を実施する文字を一定の大きさに変換します。この処理は文字の変形(縦長、横長など)を補正することと、一定の大きさにすることによって、次の「特徴抽出」や「マッチング」を 正確かつ簡易に実施するための処理と位置づけされています。
正規化
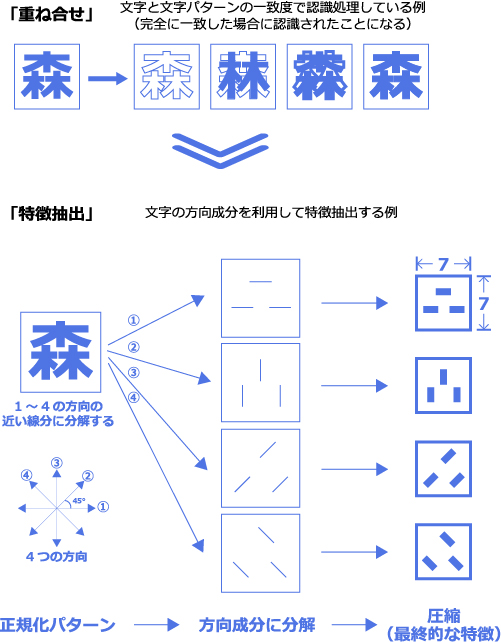
黎明期のOCR(文字認識)は、正規化された状態の文字パターンを、同じ形態で、あらかじめ登録されている標準パターンと単純な【重ね合せ】法によって比較をして、認識処理を実施していました。 しかし、この方法だと、「文字の傾き」や「字体」、「かすれ、つぶれ」などの認識が難しく、高い認識精度を得ることは困難でした。
その後、文字の形をそのまま比較して認識する方法から、いろいろな変動を吸収して、正確にOCR(文字認識)することができる方式(一旦、文字の「特徴」に変換する方式)がとられるようになって来ました。
図8は最近広く使用されている、文字の方向成分を利用した特徴の概念を示したものです。すなわち、1.で正規化された文字を図9のような上下、左右、斜め方向の4つの成分に分解して、メモリー量や処理時間を考えて、4つの成分を7×7程度までに圧縮したものを個々の文字の特徴として抽出します。この時点で、1つの文字は(7×7)×4=196個の特徴値に変換されたことになります。
OCR(文字認識)を行うためには、2.で説明した「特徴」を使って、認識したい文字をすべて、あらかじめ登録しておくことが必要です。これを「標準パターン」と呼んでいます。「標準パターン」は、いろいろな字体(明朝体、ゴシック体、教科書体など)や「かすれ」、「つぶれ」文字の認識を安定して行うために、いろいろな状態で印字された文字を平均化して作られています。その上で認識したい文字を1.、2.を経て処理された「特徴」に変換して、どの文字(標準パターン)に近いかの計算を行うわけです。
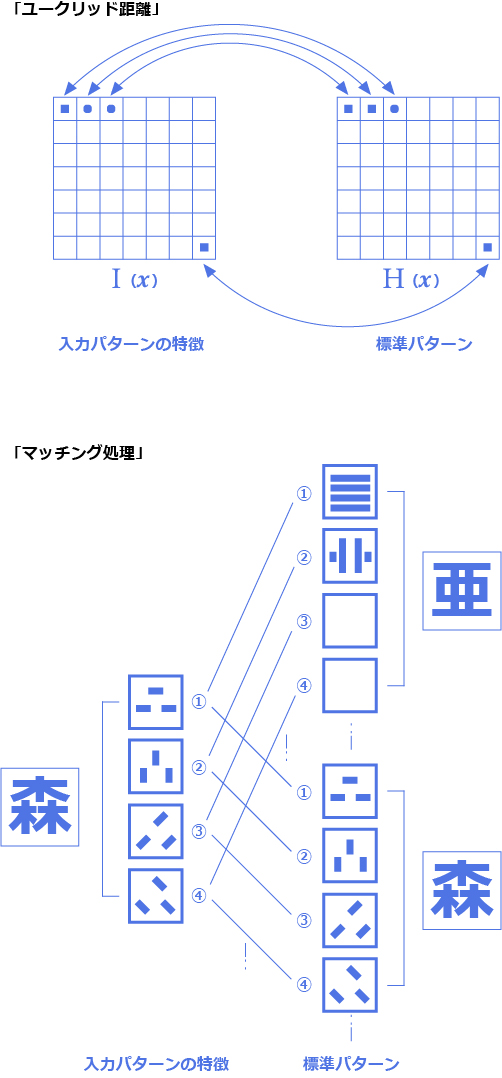
2次元パターン間の距離(似ている度合い)を計算する方法はいくつかありますが、一般に図10に示すようなユークリッド距離という方法が用いられています。対応する座標ごとに以下のような計算を行います。
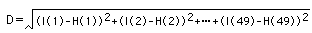
この方式により、入力された文字の特徴とすべての標準パターンとの距離計算を図11に示すように行います。そして、標準パターンと距離計算した結果、最も距離の小さいものが、認識結果となります。この処理をする場合に、距離の1番小さいものだけでなく、第2~第5位くらいまでの結果も合わせて候補文字として表示し、誤読文字の訂正に使用したり、次の知識処理で使用する方法がとられています。
入力パターンの「特徴」と「標準パターン」の1~4の方向成分毎にユークリッド距離を計算し、その値が最も小さい「標準パターン」が認識結果となります。
3.のマッチング処理では、たとえば、「夕(漢字)」と「タ(カタカナ)」や「力(漢字)」と「カ(カタカナ)」などを認識することは困難です。人間の場合も、これらを識別するには、文字列の前後関係を見て判断しているのです。
簡単に説明しますと、このように日本語の単語情報やもう少し広い意味での言語情報を使用して、より正確な認識を行うことを「知識処理」と呼んでいます。知識処理では認識された文字列の候補文字から、あらかじめ登録してある単語辞書と照合して誤読した部分を自動的に訂正するという方法が一般的に使用されています。
しかし、人間は多少誤読した部分があっても、その部分を「前後関係」や、「この文章はどのような状況での文章なのか」などの情報を使って推測することができますが、現状の「知識処理」は、まだこのレベルには至ってはおりません。
以上に示しました1.~4.の処理により、個々の文字認識が行われ、その結果が得られるのです。3.で得られた候補文字の情報を使用して図12のように行います。 「東」を「束」と誤認識したが、2位に「東」があったので、「東京」という単語辞書により自動訂正される。

以前は、第5ステップまでで文字認識は終了ですが、認識結果を元の文書の形と同じように出力し再利用できるように、この第6ステップの処理に進みます。
最近では、ほとんどのOCRソフトがWord、Excel、一太郎、PDF、HTMLなどのフォーマット出力に対応しています。これらのフォーマットに対応することにより、元の原稿とほぼ同じ形の電子化原稿を得ることができます。

